Offline content with service workers
My experience implementing service workers to cache and serve content offline.
Service workers can do a lot more than make web pages work offline but for most people, myself included, this will be their first experience with them. I recently implemented a simple offline page for my blog and was surprised with how easy it was. Full of confidence, I wanted to do more. I decided to start saving blog posts for offline reading and things escalated quickly. I soon learnt the rabbit hole is deep.
This is not a criticism of service workers, it's an indication of how powerful and versatile they are. I think in time, as the concepts become more familiar, and the complexities are abstracted away, offline content will become common place. In fact, I drank the kool-aid and can see why many people think that, within a few years, offline content will become as ubiquitous in web development as responsive design today.
Having said that, there are a few things I wish I had known before getting started.
Browser support & caching permalink
Service workers are an easy candidate for progressive enhancement and on the surface, it's easy to check for support before registering a service worker. You do that like this:
if ("serviceWorker" in navigator) {
// Yay, service workers work!
navigator.serviceWorker.register("/sw.js");
}It seems simple enough but there is one gotcha. If you look at the MDN page for the service worker cache API, you will see that different versions of Chrome support different caching methods. This means that, despite diligently checking for feature support, versions of Chrome between 40 and 45 will get an error when using the addAll method. This is less of a problem now than it was when these versions were more widely used. I checked Can I Use and at the time of writing this, it looks like it might impact around 1.15% of users.
I read several blogs and tutorials on getting started with service workers, some advocate using only put rather than addAll, others recommend using a cache pollyfill, while others still make no mention of it. Obviously these were all written at different times and it took me a lot of research to work out what the right approach was.
In the end, with such a small number of users, that is only getting smaller, I opted to check for the addAll method and treat browsers that don't support it, like those that don't support service workers at all.
So, my feature detection now becomes:
if (
"serviceWorker" in navigator &&
(typeof Cache !== "undefined" && Cache.prototype.addAll)
) {
// Yay, this is a problem we didn't need to have!
navigator.serviceWorker.register("/sw.js");
}This is a bit verbose, and I'm really going out of my way here just to avoid a console error, but I tested this in all major browsers, including critical versions that don't support the addAll method, and I'm happy with it. It was so much fun!
Where to put service workers permalink
When you register a service worker you point to a JavaScript file with the service worker logic, and this brings me to the second thing I wish I'd known. That is, if you want to implement service workers across your domain, you must place the service worker in the root directory of your site. For security reasons, service workers only control pages in the same directory as the service worker or below. Effectively this means, not in your site's JavaScript directory as I attempted at first. I'm sure this was written as clear as day, somewhere that was obvious to everyone but me.
While on this topic, it's worth mentioning that service workers only work over HTTPS or localhost domains. Luckily for me my blog was already configured to redirect HTTP traffic to HTTPS. If you can do this, it's a great idea, if not, you could check you are on a secure domain before registering a service worker.
Can we service worker yet? permalink
Yes, we are now ready to service worker! When getting started I recommend reading, Jake "The Service Worker" Archibald's Offline Cookbook. It's still a great place to start and the links and references contain a wealth of information.
You'll soon learn that, where offline content is concerned, there are 3 main events we listen for in a service worker:
- install,
- activate, and
- fetch.
The install event is fired only once when the service worker is first registered. Here we setup the cache prime it with essential resources. My install event is pretty simple, nothing special here. I cache the homepage, CSS and an offline page:
var CACHE_NAME = "v1::madebymike";
var urlsToCache = ["/", "/offline.html", "/css/styles.min.css"];
// Install
self.addEventListener("install", function(event) {
event.waitUntil(
caches.open(CACHE_NAME).then(function(cache) {
return cache.addAll(urlsToCache);
})
);
});The activate event is fired after install and every time you navigate to the domain managed by the service worker. It's not fired for subsequent navigation between pages on the same domain.
My activate event is also pretty standard. I'm only using one cache for my service worker. This pattern checks the names of any caches to ensure they match the variable CACHE_NAME, if they don't, it will delete them. This gives me a manual means of invalidating my service worker cache.
self.addEventListener("activate", function(event) {
event.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames
.filter(function(cacheName) {
return cacheName !== CACHE_NAME;
})
.map(function(cacheName) {
console.log("Deleting " + cacheName);
return caches.delete(cacheName);
})
);
})
);
});Finally, the fetch event is fired every time a page is requested. The fetch event is intercepted regardless of whether the user is offline or not. Like I said earlier service workers != offline content. Offline content is just one implementation of service workers. And this is really good news! Service workers have the ability speed up everyday web browsing, like, a lot.
Here is my first example of a fetch event. It's really little more than custom error page, but it's a start.
self.addEventListener("fetch", function(event) {
e.respondWith(
// If network fetch fails serve offline page form cache
fetch(event.request).catch(function(error) {
return caches.open(CACHE_NAME).then(function(cache) {
return cache.match("/offline.html");
});
})
);
});A better service worker (down the rabbit hole) permalink
At this point I was pretty happy with myself and if you want to implement offline content, aiming for the above is a great start. Brazened by my success I could see the potential. I needed to cache blog posts for offline reading, and where possible, I needed to return pages from the cache for connected users.
It took me a lot of testing and several mistakes to finally arrive at this pattern. You need to be really careful when serving cached pages by default. You could end up showing really old content, or even breaking your site.
self.addEventListener('fetch', function(event) {
var requestURL = new URL(event.request.url);
event.respondWith(
caches.open(CACHE_NAME).then(function(cache) {
return cache.match(event.request).then(function(response) {
// If there is a cached response return this otherwise grab from network
return response || fetch(event.request).then(function(response) {
// Check if the network request is successful
// don't update the cache with error pages!!
// Also check the request domain matches service worker domain
if (response.ok && requestURL.origin == location.origin){
// All good? Update the cache with the network response
cache.put(event.request, response.clone());
}
return response;
}).catch(function() {
// We can't access the network, return an offline page from the cache
return caches.match('/offline.html');
});
});
});
);
});
This pattern always attempts to serve content from the cache first, but at the same time I start a network request. If the network request resolves successfully, and is not an error page, I update the cache. This means that when a user visits my website, they will see the last cached version, not necessarily the latest version. On a subsequent visit or a refresh, they will retrieve the updated page from the cache. If I make major changes, such as to CSS and I want to manually invalidate the service worker cache, I can change the CACHE_NAME in my service worker script.
A better offline page (deeper down the rabbit hole) permalink
The generic offline page, from my first fetch example, is still served when the content is not cached and the network request fails. I wanted to do more with this. If we can't show the page they want, I thought it would be helpful to list pages the user has available in their cache. So I went down the rabbit hole again.
There is a method for communicating with service workers and web workers called the channel messaging API.
IMPORTANT UPDATE:
I don't need to use the channel messaging API to get a URL from the cache in this example (Thanks to Nicolas Hoizey for brining that to my attention). The channel messaging API is useful when you want to respond to an event that only the service worker is aware of. In this case, since I am only grabbing a list of pages fron the cache I can access the window.caches object in the offline page. The only thing the service worker is aware of that my ofline page is not, is the CACHE_NAME variable. It contains the cache version and I didn't want to update it in multiple places each time it changed, but since it follows a predictable pattern I can do something like the following:
// Get a list of cache keys
window.caches.keys().then(function(cacheNames){
// Find the key that matches my cacheName
cacheName = cacheNames.filter(function(cacheName) {
return cacheName.indexOf("::madebymike") !== -1;
})[0]
// Open the cache for that key
caches.open(cacheName).then(function(cache) {
// The rest of this function is very similar to the Channel messaging API example
// where I fetch and return a list of URLs that are cached for offline reading
})
}Channel messaging API permalink
This is the old method I used to fetch cached pages from the service worker. Although it turned out I didn't need to message the service worker to do this, it's still a valuable technique for other purposes.
In the service worker, I listen for a message event. Once received, I get a list of pages from the cache that match the URL pattern for blog posts on my site and post a response back to the offline page.
self.addEventListener("message", function(event) {
caches.open(CACHE_NAME).then(function(cache) {
return cache
.keys()
.then(function(requests) {
var urls = requests
.filter(function(request) {
return request.url.indexOf("/writing/") !== -1;
})
.map(function(request) {
return request.url;
});
return urls.sort();
})
.then(function(urls) {
event.ports[0].postMessage(urls);
});
});
});In my offline page I send a message to the service worker and listen for a response. It's not very clever. At the moment it doesn't matter what message I post, I will always get the same response. But this is sufficient for now and I didn't want to complicate it more than necessary.
var messageChannel = new MessageChannel();
messageChannel.port1.onmessage = function(event) {
// Add list of offline pages to body with JavaScript
// `event.data` contains an array of cached URLs
};
navigator.serviceWorker.controller.postMessage("get-pages", [
messageChannel.port2
]);My worst case offline experience now looks something like this:
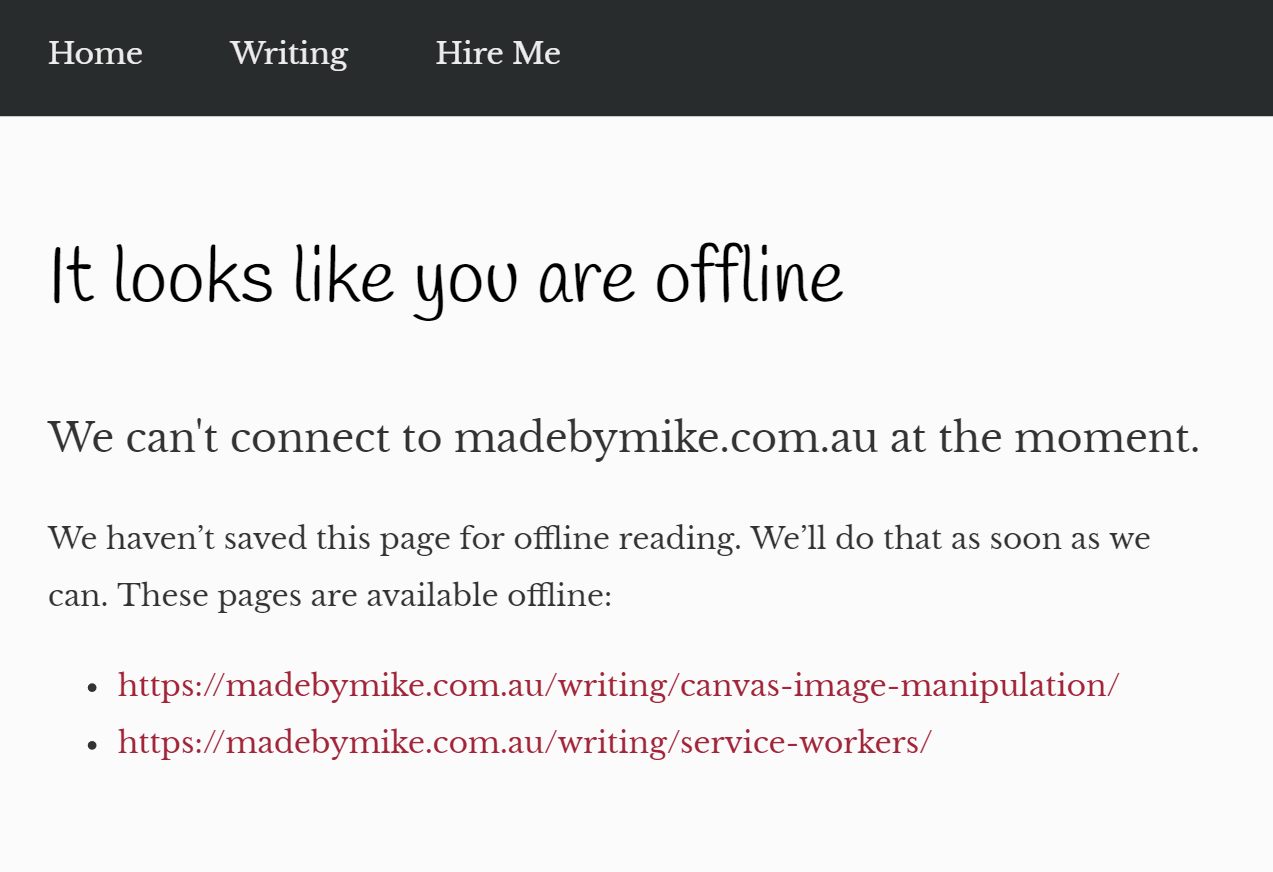
What next? permalink
I'd like to give users an indication of when they are reading something offline. I think this could be helpful, and in poor network conditions it might not always be obvious. This would probably would use the message API as well, but I might also investigate push notifications. I'll update this post if I ever get around to it.
I hope explaining my experience implementing offline content can help make it easier for you or just inspire you to get started. I think the most difficult thing was understanding the impact of choices when serving cached content to all users. Making sure you get this right is important and it takes some time to understanding how service workers, and caching in general works. I'm not an expert at this so please, if I've got anything wrong, let me know so I can update it.